前言
下面是正文:
编译和转译
定义
编译(compile)是把一门编程语言转成另一门编程语言,一般是指高级语言到低级语言。
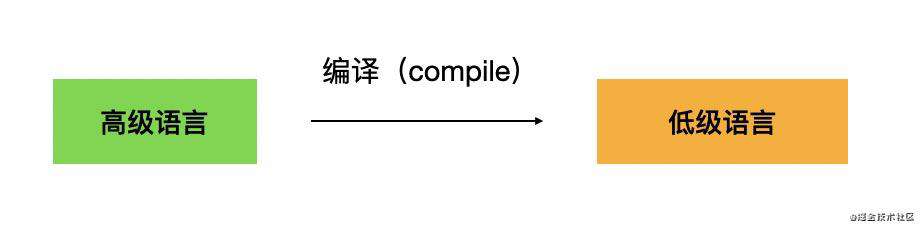
转译(transpile)是一种特殊的编译,它是从高级语言到高级语言的编译,比如从 C++ 转 Java,从 Typescript 转 Javascript、从 Javascript 转 Javascript、从 Css 转 Css 等。

前端领域为什么需要转译器
前端领域主要是 html、css、js:
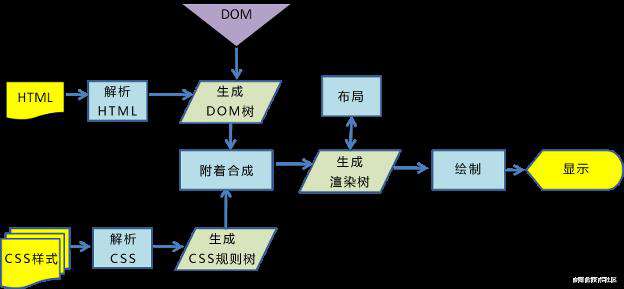
html、css 是从源码 parse 成 dom 和 cssom,然后生成 render tree 交给渲染引擎来渲染的。是从源码开始解释。
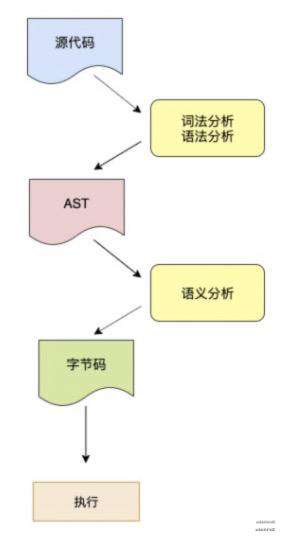
js 是一门脚本语言,也是在运行时把源码 parse 成 AST,然后转成字节码,解释执行的。也是从源码开始。
目标的产物就是源码,所以前端场景下就自然需要用到各种源码到源码的转译器。
前端领域需要哪些转译器
转译是对源码做修改之后生成源码,是 source to source 的。前端领域需要哪些转译器呢?
Javascript
- es 版本更新快, es 2015、es 2016、es 2017 等新特性目标环境不支持,但是却想开发时用,就需要转译器把这些特性转成目标环境支持的,比如 babel、typescript。

- Javascript 是动态类型语言,编译期间没有类型的概念,没法提前进行类型检查。想给 Javascript 加入类型的语法语义,但是需要编译完后会把类型信息去掉,这也需要转译器,比如 typescript、flow。

-
有些框架需要一些语法糖,比如 react 的 React.createElement 写起来太过麻烦,希望开发时能用类似 xml 的方式来书写,由转译器来把这些语法糖编译成具体的 api,比如 jsx。
-
需要在编译期间对代码进行压缩和各种优化(死代码删除等),然后转成目标代码,比如 terser。

- 需要在编译期间检查出一些代码规范的错误,比如 eslint。

Css
- 需要扩展一些能力,比如变量、函数、循环、嵌套等等,使得 css 更容易管理,比如 scss、less、stylus 等 DSL(domain specific language),或者 css next,这些都分别通过 scss、less、stylus、postcss 等转译器来转成目标 css。

- 需要处理兼容性前缀(autoprefixer)、对 css 进行规范检查(stylelint)、css 模块化 (css modules)等,这些通过 postcss 转译器支持。

Html
- 和 css 一样,也要扩展一些能力,比如继承、组合、变量、循环等等,这些是 pug、moustache 等模版引擎支持的,也有各自的转译器来把源码在编译期间转成目标代码(这个转换也可能是在运行时做的)。

- 支持各种内容转 html,比如 markdown 转 html 等,这可以通过 posthtml 来做转译。

总之,前端领域需要很多转译器。
那这么多转译器,它们的原理是什么呢?
转译器原理
编译流程
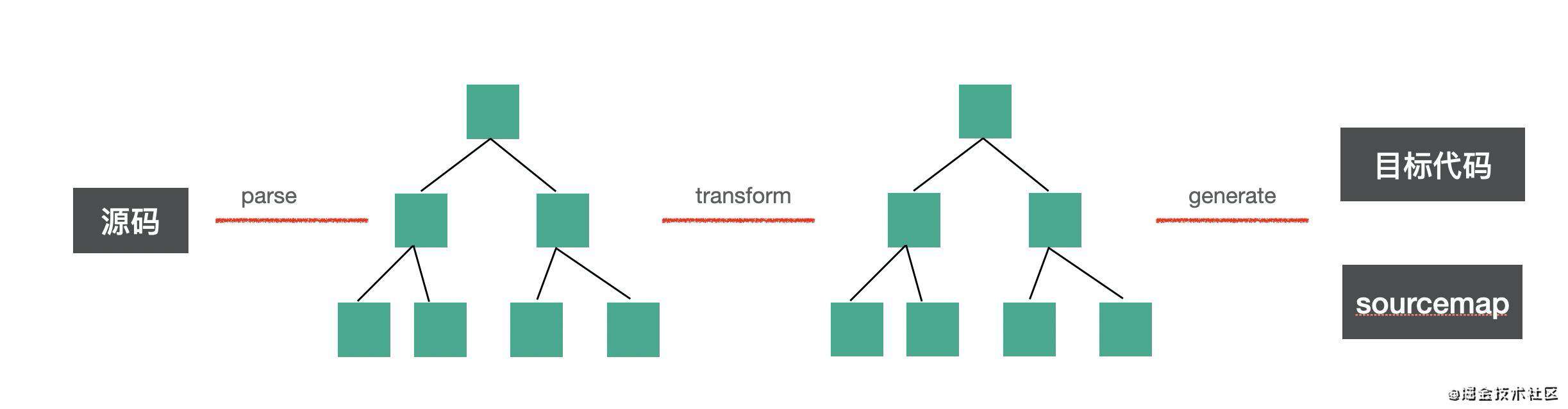
其实这些转译器编译流程都类似,都需要 parse、transform、generate 这 3 个阶段。
(虽然具体的名字可能不一样,比如 postcss 把 genenrate 叫做 stringify,vue template compiler 把 transform 阶段叫做 optimize)
为什么需要这3个阶段呢?
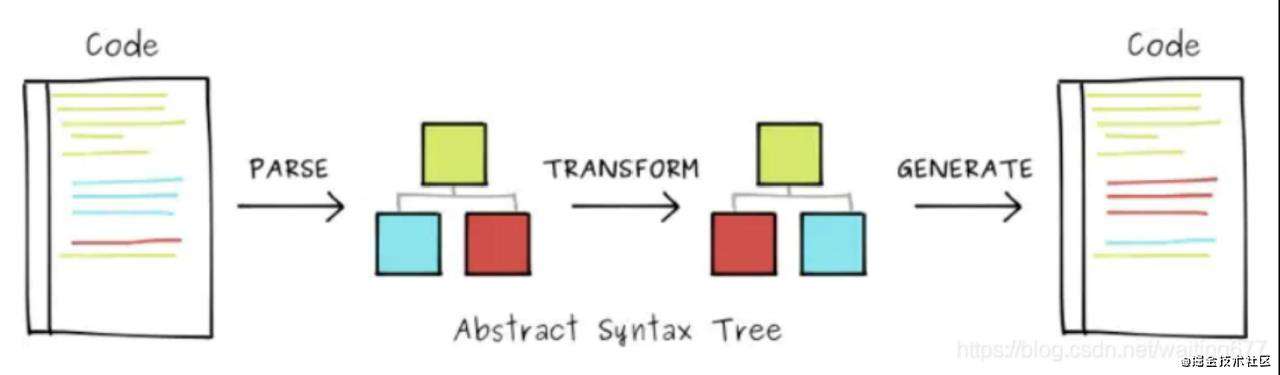
转译器转换前后都是源码字符串,要做转换,就要先理解代码,计算机理解代码的方式就是通过一定的数据结构来组织源码中的信息,这种数据结构就是抽象语法树。
之所以说是抽象,是因为忽略了逗号、括号等分隔符。之所以是树,是因为代码一般都是嵌套的关系,需要用树的父子关系来表示源码的嵌套关系。 所以抽象语法树是最适合计算机来理解代码的数据结构。
理解了代码(生成 AST)之后,就要进行各种转换了,比如 terser 会做死代码删除等编译优化、babel 会做 es next 转目标环境 js,typescript compiler 会对 AST 进行类型检查, postcss 也会对 AST 做一系列的处理,等等。这些都是针对 AST 的分析和增删改。
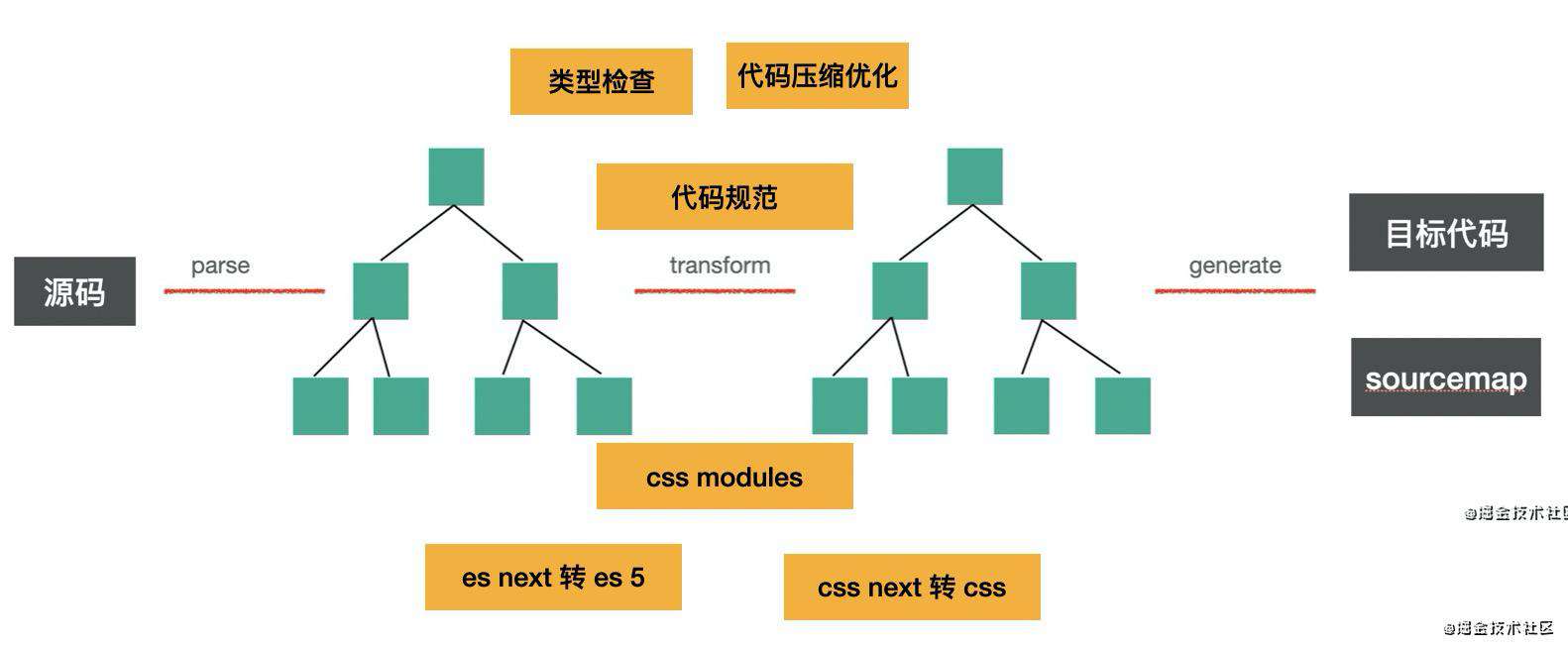
但,虽然不同的转译器会对 AST 做不同的处理,它们的整体编译流程是类似的,这是转译器的通用原理。
sourcemap
转译器有个特点,就是都有 sourcemap。 sourcemap 是生成的代码和源码之间的映射关系,通过它就能映射到源码。转译器都是源码转源码的,自然都会有 sourcemap。
{
version : 3,
file: "out.js",
sourceRoot : "",
sources: ["foo.js", "bar.js"],
names: ["src", "maps", "are", "fun"],
mappings: "AAgBC,SAAQ,CAAEA"
}
比如上面就是一个 sourcemap 文件,对应字段的含义如下:
-
version:source map的版本,目前为3。
-
file:转换后的文件名。
-
sourceRoot:转换前的文件所在的目录。如果与转换前的文件在同一目录,该项为空。
-
sources:转换前的文件。该项是一个数组,因为可能是多个源文件合并成一个目标文件。
-
names:转换前的所有变量名和属性名,把所有变量名提取出来,下面的 mapping 直接使用下标引用,可以减少体积。
-
mappings:转换前代码和转换后代码的映射关系的集合,用分号代表一行,每行的 mapping 用逗号分隔。
具体细节推荐阮一峰老师的文章
sourcemap 用在哪?
我们平时用 sourcemap 主要用两个目的:
调试代码时定位到源码
chrome、firefox 等浏览器支持在文件末尾加上一行注释
//# sourceMappingURL=http://example.com/path/to/your/sourcemap.map
可以通过 url 的方式或者转成 base64 内联的方式来关联 sourcemap。浏览器会自动解析 sourcemap,关联到源码。这样打断点、错误堆栈等都会对应到相应源码。
线上报错定位到源码
开发时会使用 sourcemap 来调试,但是生产可不会,要是把 sourcemap 传到生产算是大事故了。但是线上报错的时候确实也需要定位到源码,这种情况一般都是单独上传 sourcemap 到错误收集平台。
比如 sentry 就提供了一个 sentry webpack plugin 支持在打包完成后把 sourcemap 自动上传到 sentry 后台,然后把本地 sourcemap 删掉。还提供了 sentry-cli 让用户可以手动上传。
当然,不只是 sentry,类似的分析平台,比如字节的 dynatrace 也同样支持

平时我们至少在这两个场景(开发时调试源码,生产时定位错误)下会用到 sourcemap。
sourcemap 的原理
知道了 sourcemap 的作用,那么 sourcemap 是怎么生成的呢?
具体生成的逻辑可以由 source-map 这个 mozilla 提供的包来完成,我们只需要提供每一个 mapping,也就是源码中的行列号,目标代码中的行列号。
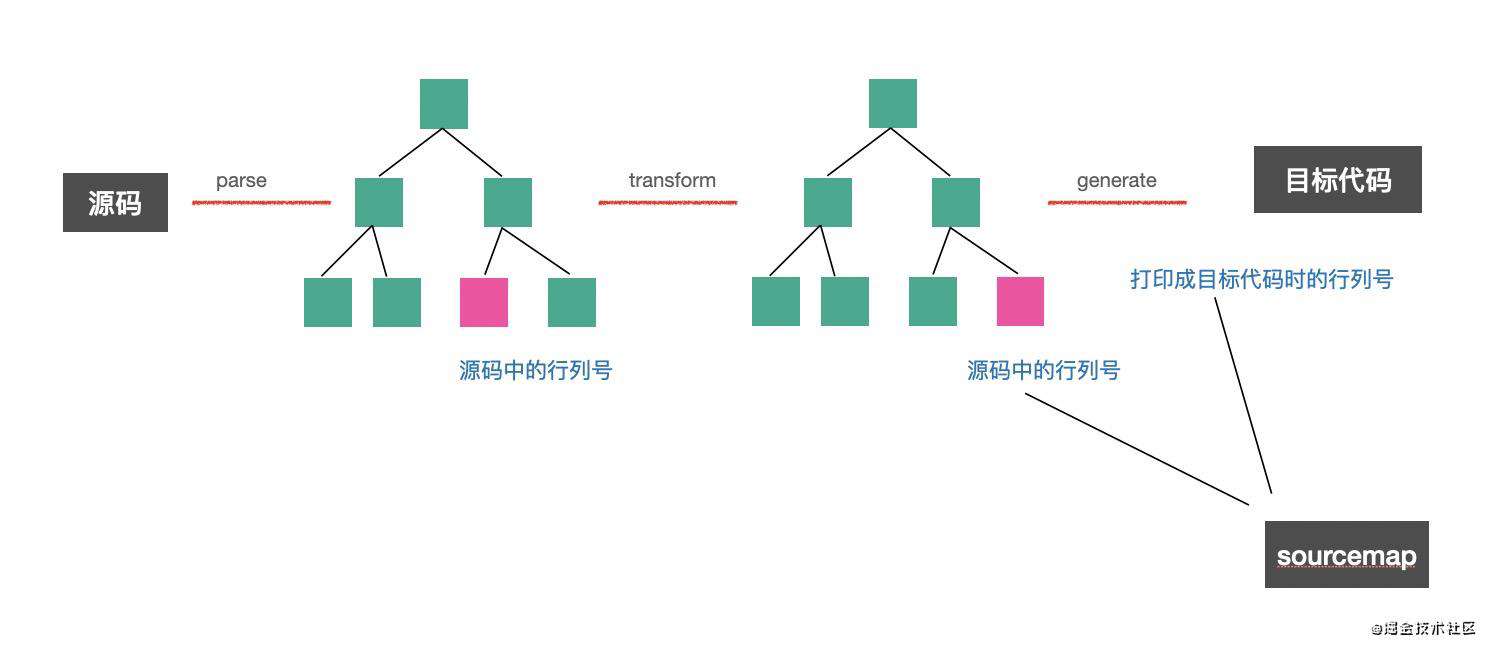
当源码 parse 成 AST 的时候,会在 AST 中保留它在源码中的位置(line、column)
AST 进行转换并不会修改这个行列号
生成目标代码的时候,又会计算出一个新的位置(line、column)
这样两个位置合并起来就是一个 mapping。所有 AST 节点的 mapping 就能生成完整的 sourcemap。
这就是 sourcemap 生成的原理。
前端领域的转译器
介绍了转译器的通用原理和 sourcemap 的原理,我们来看一下具体的转译器。
babel

babel 是将 es next、typescript、flow、jsx 等语法转为目标环境中支持的语法并引入缺失 api 的 polyfill 的一个转译器。
它的编译流程也是标准的 parse、transform、generate 3步,
它提供了 api 和命令行的使用方式。
babel 的 api
babel 7 包含这些包:
@babel/parser 将代码转为 ast,可以使用 typescript、jsx、flow 等插件解析相关语法
@babel/traverse 遍历 ast,调用visitor的函数
@babel/generate 打印 ast 成目标代码,生成sourcemap
@babel/types 创建和判断 ast 节点
@babel/template 根据代码模版批量创建 ast 节点
@babel/core 转换源码成目标代码的完整流程,应用 babel 的内部转换插件
基于这些包的api,可以完成各种 JS 代码的转换。
babel api 的 demo
我们用上面的 api 完成一个在 console.log 和 console.error 中插入一些参数的功能。
思路就是当遇到 console.* 对应的 CallExpression 节点的时候,在 arguments 参数重插入相应的内容。
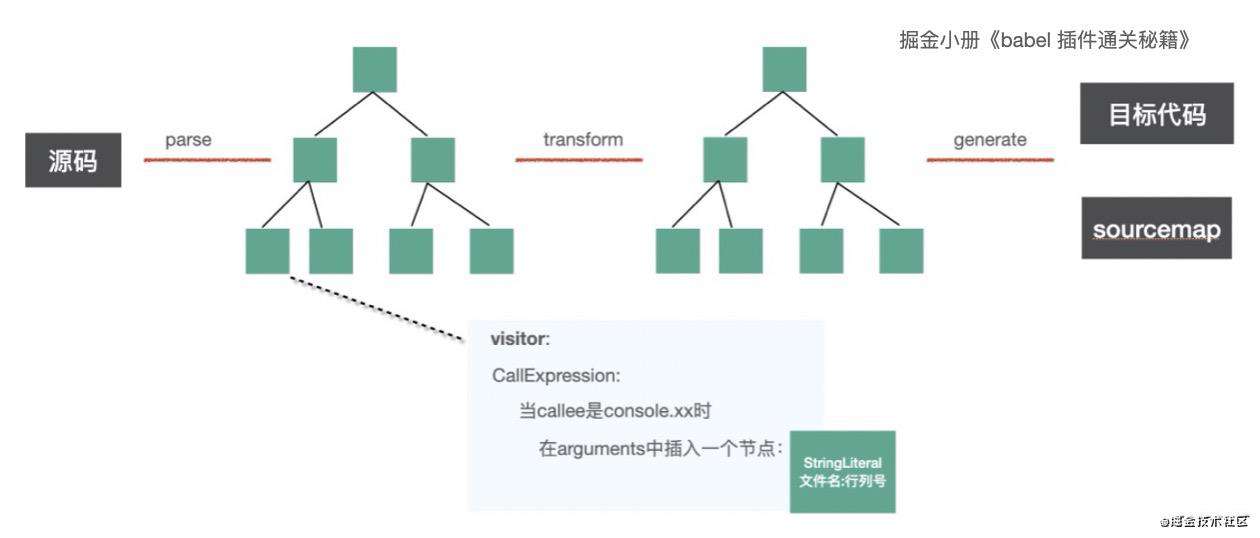
我们用代码实现一下:
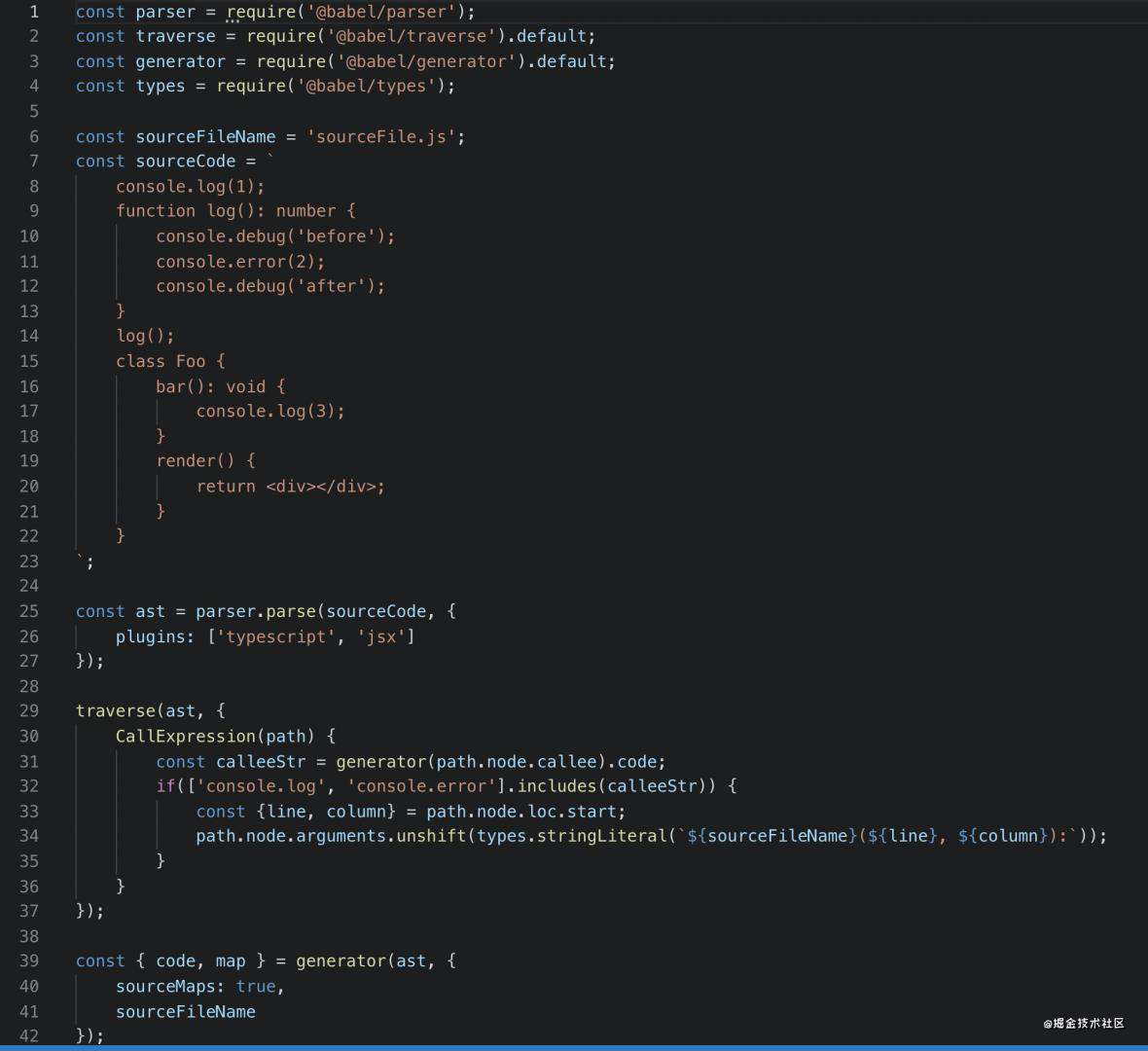
运行看下效果:
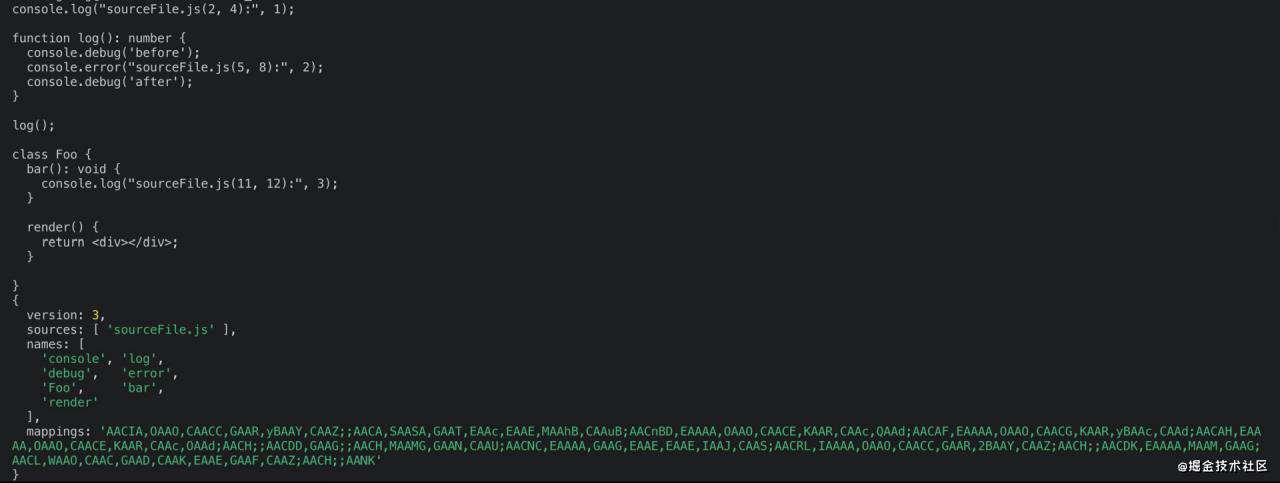
可以看到 console.log、console.error 中插入了相应的参数,并且也生成了 sourcemap。
更多 babel 的原理和案例可以关注我即将上线的小册《babel插件通关秘籍》。
typescript compiler

typescript 给 Javascript 扩展了类型的语法语义,会首先进行类型推导,之后基于类型对 AST 进行检查,这样能够在编译期间发现一些错误,之后会生成目标代码。
typescript compiler 分为 5 部分:
-
Scanner:从源码生成 Token (词法分析)
-
Parser:从 Token 生成 AST(语法分析)
-
Binder:从 AST 生成 Symbol (语义分析--生成作用域,进行引用消解(就是引用的变量是否被声明过))
-
Checker:类型检查 (语义分析--类型检查)
-
Emitter:生成最终的 JS 文件 (目标代码生成)

其实这些阶段也同样可以对应的 parse、transform、generate 的大阶段上(babel 也同样会进行作用域的语义分析,类似 tsc 的 binder)。
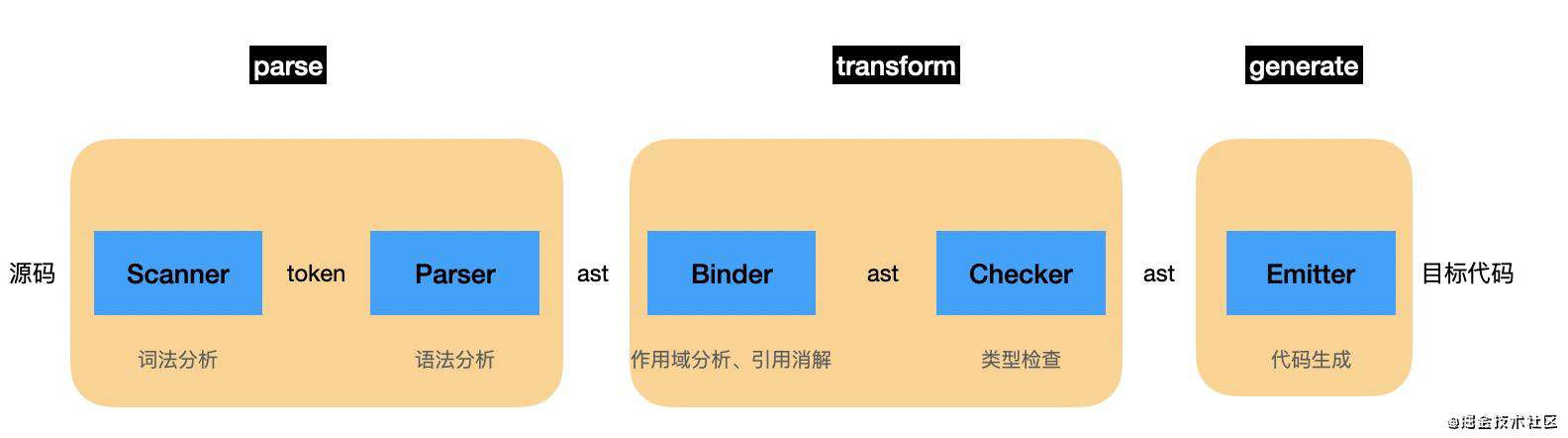
(一般是在遍历的过程中进行作用域的生成,所以语义分析放在了 transform 阶段。图中没有画出 AST 转换的部分,但是是有的)。
typescript compiler 的编译流程也可以对应到转译器的 3 个阶段,只不过 typescript compiler 多做了一些语义分析(类型检查)。
typescript compiler 的 api
typescript compiler 的 api 并不稳定,连文档都没有,但是在 typescript 包暴露了出来的,是可用的。
我们分别看一下 typescript 中进行 parse、transform、generate 的 api:
parse

ts 的类型往往要从多个文件中获得,需要先创建 Program,然后从中拿某一个路径对应的 AST,也就是 SourceFile 对象。(这个和 babel 不同,babel 是直接源码 parse 成 AST 了,这里要两步)
transform
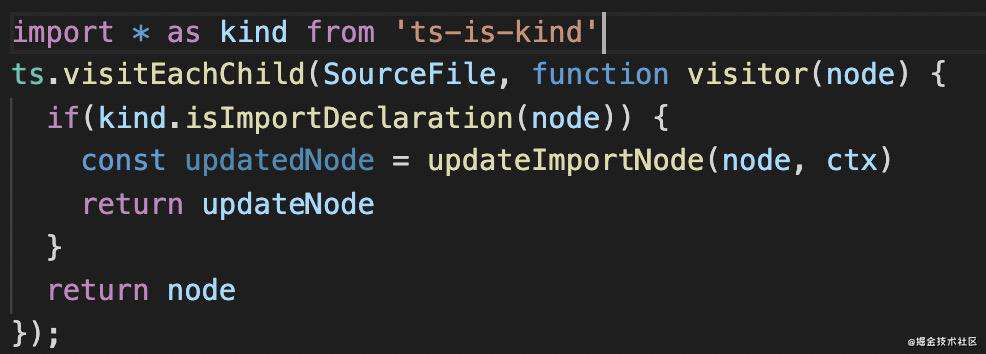
通过 ts.visitEachChild 遍历 AST,通过 ts.createXxx 生成 AST,通过 ts.updateXxx 替换 AST 通过 ts.SyntaxKind 来判断 AST 类型。
分别对应 @babel/traverse、 @babel/types 包的一些 api,你会发现当你学会了一个转译器,其余的转译器大同小异。
generate
通过 printer 打印 AST 成目标代码。

tsc vs babel
我们知道 babel 7 以后 @babel/parser 已经支持解析 typescript 的语法了,那么我们是用 babel 编译 ts 呢,还是用官方的 typescript compiler 呢?
我觉得用 babel 编译 ts,单独执行 tsc --noEmit 进行类型检查是比较好的方案。
原因有这几点:
-
babel 可以编译几乎全部的 ts 语法,有几个不支持的情况也可以绕过去。
-
babel 生成代码会根据 targets 的配置来按需转换语法和引入 polyfill,能生成更小的目标代码。而 typescript 还是粗粒度的指定 es5、es3 的 target,不能按需转换,引入 polyfill 也是在入口全部引入,生成的代码体积会更大。
-
babel 插件丰富,typescript transform plugin 知道的人都不多,更不用说生态了。
-
babel 编译 ts 代码不会进行类型检查,速度会更快,想做类型检查的时候可以单独执行 tsc --noEmit。
综上,用tsc做类型检查,用babel做代码转换是更好的选择。
eslint

eslint 可以根据配置的规则进行代码规范的检查,部分规则可以自动修复。
用户配置一些 rule,eslint会基于这些 rule 来对 AST 进行检查。
它同样也提供了 api 和命令行两种方式,当做工具链开发的时候就会用到 api 的方式。

eslint 插件的 demo
我们来写一个 eslint 的 rule:检测到 console.time 就报错,并且还可以通过 --fix 自动删除
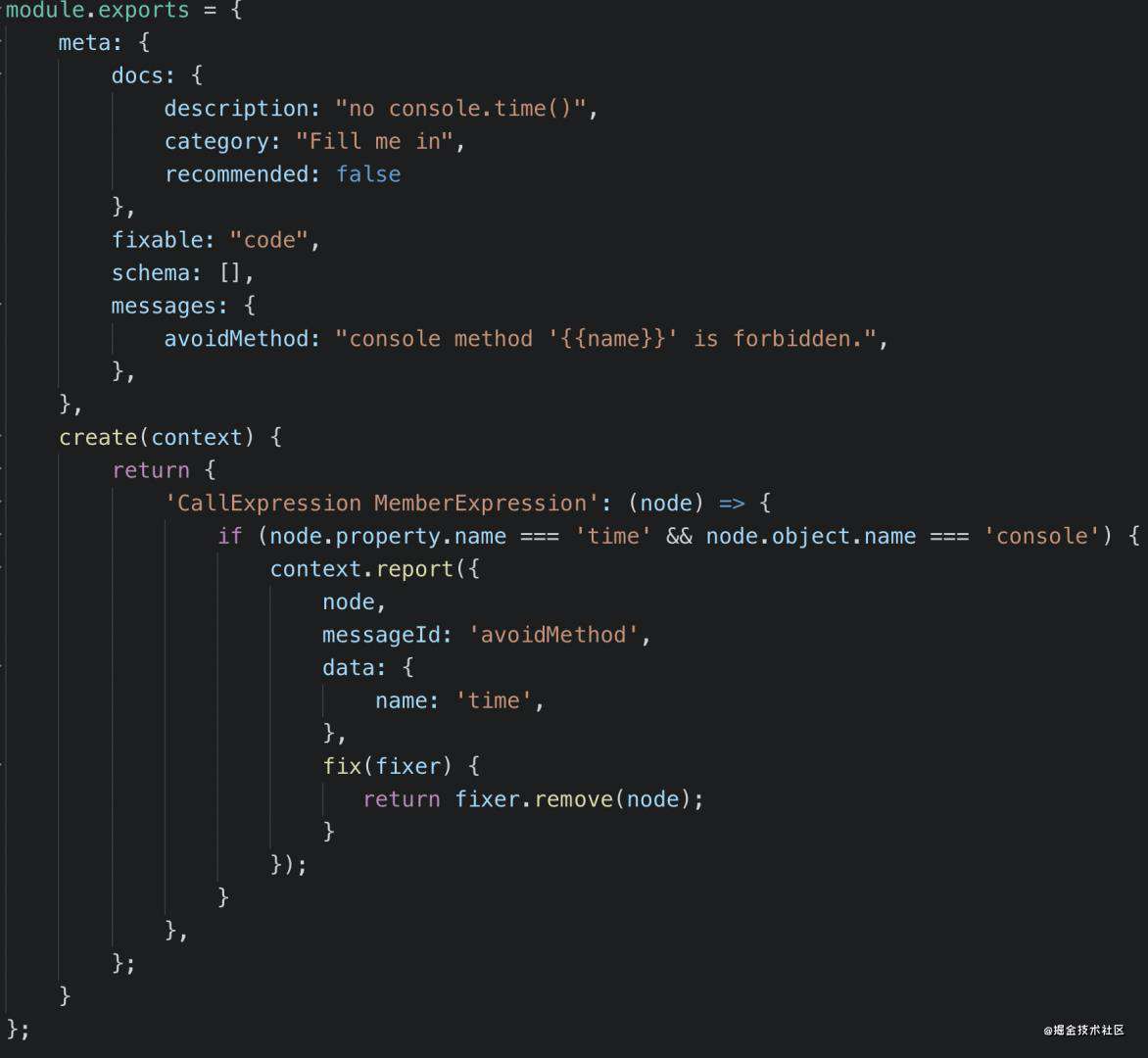
其实思路和 babel 插件差不多,都是 visitor 模式,声明对什么类型的 AST 节点进行什么操作,只不过形式有些不同。
在 meta 里声明一些元信息,比如文档中展示什么信息、是否可以 fix、报错信息是什么等。
create 返回的 visitor 中可以拿到一些 api,比如调用 report 的 api 就会进行报错,如果制定了 fix 方法,还可以在用户指定 --fix 参数的时候自动进行fix,比如这里的 fixer.remove 来删除 AST。
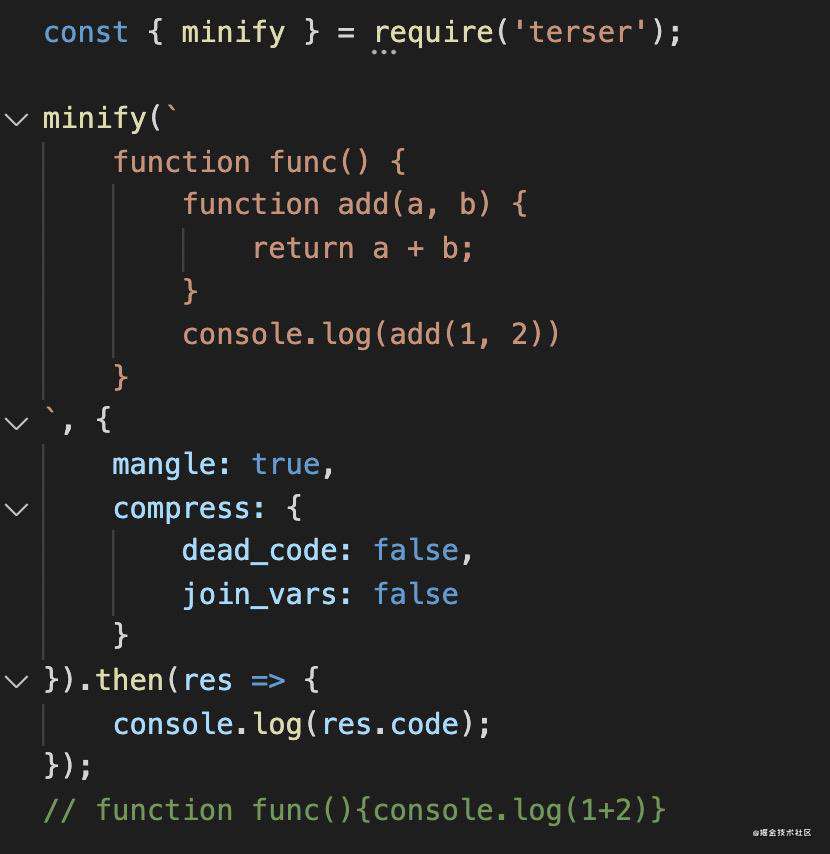
terser
terser 可以对 JS 代码进行压缩、混淆、死代码删除等编译优化的转译器。基本上它也是前端工具链中必备的工具。
最初是 uglifyjs,但是因为它并不支持 es6 以上代码的 parse 和优化,所以又写了 terser。
terser 支持各种压缩和混淆选项,可以在文档中查看细节。
它同样支持 api 和命令行的使用方式。api 的方式如下:
swc

swc 是用 rust 写的 JS 转译器,特点就是快。
Javascript 写的 parser 速度再快也绕不过是解释型语言的缺点,运行时从源码进行 parse,然后解释执行,会比编译型语言慢。
它的目标是替代 babel,具体能否替代,看后续发展吧。
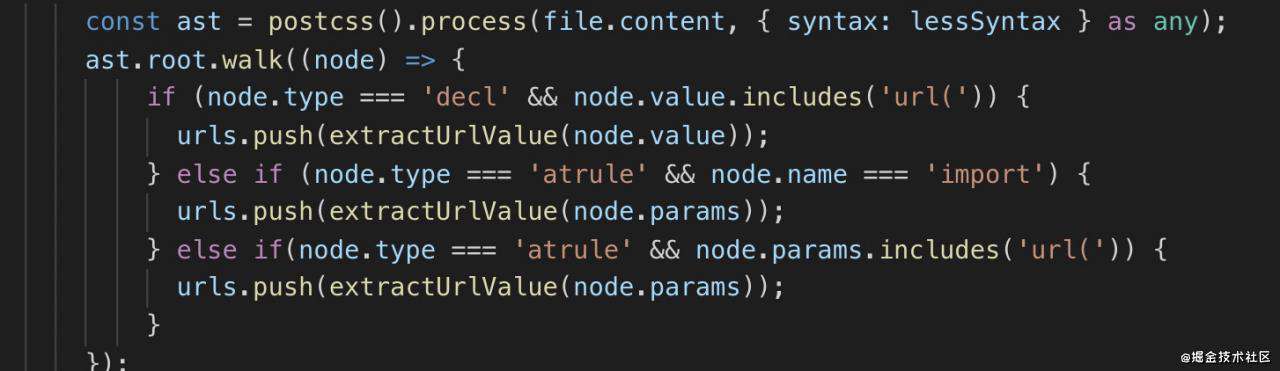
postcss

css 的转译器,类似 babel,也支持插件,并且插件生态很繁荣。
它提供了 process、walk、stringify 的 api, 分别对应 parse、transform、generate 3个阶段。
比如下面是一段提取 css 中所有依赖(url()、@import)的代码
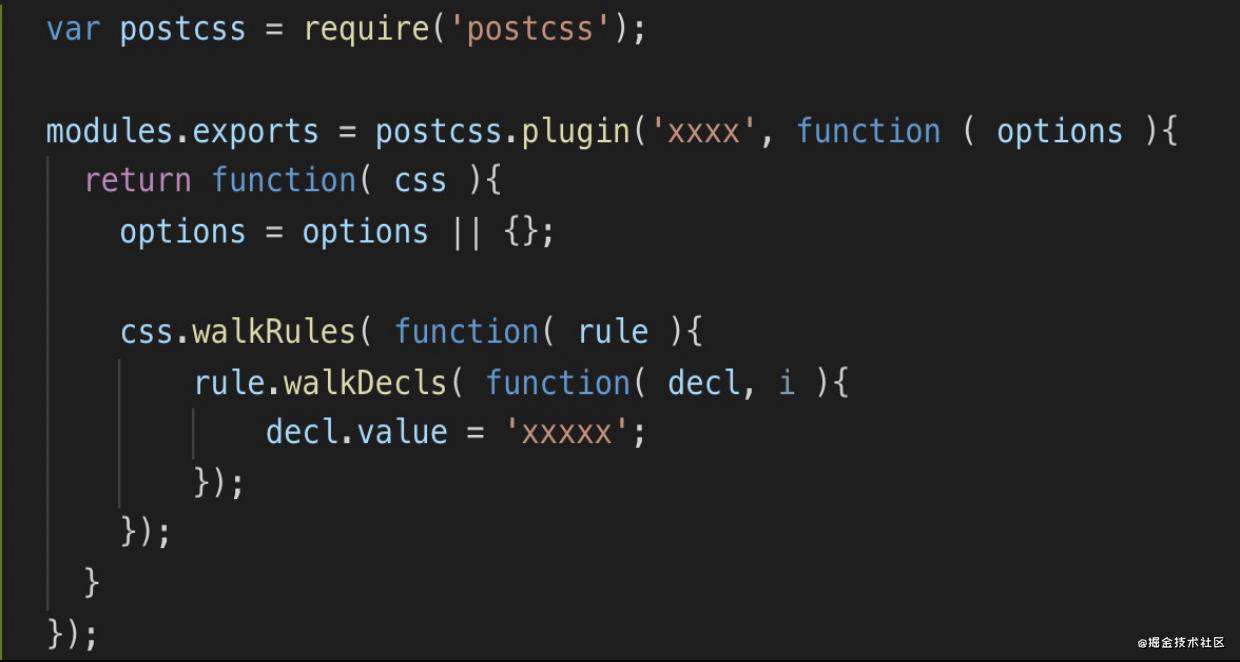
postcss 的插件
postcss 像 babel 一样,有着强大的插件生态。
它的插件的形式如下:
插件同样是对 AST 的增删改,但是也有区别,并不是像 eslint、babel 插件一样的 visitor 模式,而是需要自己去遍历 AST,找出目标 AST 再进行转换。(typescript compiler 的 api 也是这样,比如它的ts.forEachChild)。
我们可以总结出来,转译器的操作 AST 的方式就分为两种,visitor 模式和手动查找模式,
- visitor 模式的实现包括: babel、eslint
- 手动查找方式的实现包括: typscript compiler、postcss、posthtml
posthtml

posthtml 从名字就可以看出来是对 html 进行转译的,支持插件。
比如一个 posthtml 插件的例子:
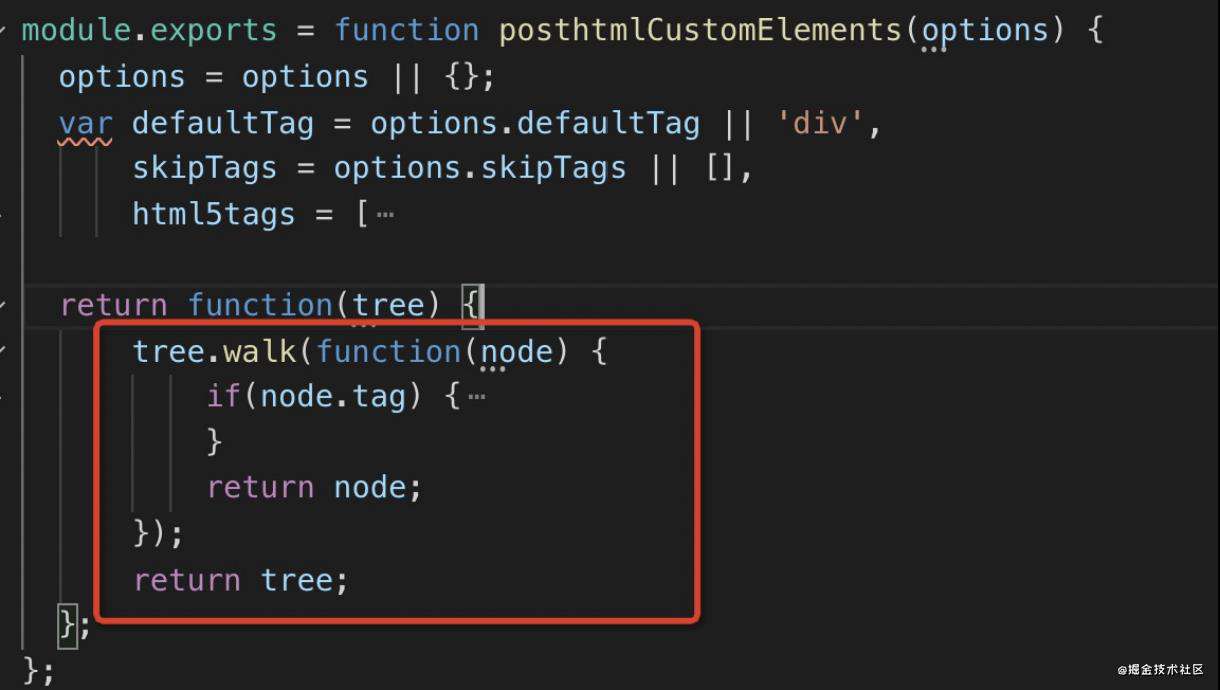
遍历方式是手动查找的方式,和 postcss 类似。
prettier

prettier 是用于格式化代码的转译器,和其他转译器主要作用在 transform 阶段不同,它主要的逻辑是在 generate 阶段支持更友好的格式,比如支持代码太长的时候自动换行。
它和 eslint、stylelint 有一些重合的部分,一般会把 lint 工具的格式化相关的 rule 禁用掉,只保留一些错误的检查,比如 eslint-prettier、stylint-prettier 插件就是做这个的。
prettier 更多是用命令行的方式,但工具链开发的时候也会用到 api。

它能格式化的不只是 js、css,还有很多其他的代码

转译器在项目中的使用
上面我们介绍了一系列的转译器,它们各自完成不同的功能,那这些转译器是怎么用在我们项目中的呢?
转译器在项目中的应用有三种方式:
-
ide 的插件。在写代码的时候对代码实时进行 lint、类型检查、格式化等,比如常用的 eslint vscode插件、typescript vscode 插件(这个是内置的)等。
-
git hooks。通过 husky 的 git commit hook 来触发执行。比如 prettier,这个只需要在代码提交的时候格式化一下。
-
通过打包工具来调用。转译器针对的是单个文件,打包工具针对的是多个文件,在打包的过程中处理到每一个文件会调用相应的转译器来处理,比如 webpack 的 loader。
总结
我们首先明确了编译和转译的区别,探讨了下为啥前端领域需要转译器,都需要转译器做什么。
然后学习了转译器的通用流程: parse、transform、genenrate,并且了解了 sourcemap 的作用和原理。
之后我们具体了解了 babel、typescript、eslint、terser、swc、postcss、posthtml、prettier 等转译器,了解了他们的作用和使用方式,还有插件的写法。
最后我们总结了转译器在项目中的 3 种使用方式: ide 插件、git hooks、打包工具的 loader。
希望这篇文章能够让你对转译器有个全面的认识。
(这是我去华为分享的《前端领域的转译打包工具链》的内容的上半部分,内容比较多,拆成了两篇文章。 下一篇文章是 《前端领域的转译打包工具链》 的下半部分,会讲模块化、打包工具、解释器以及前端工程化的闭环。)
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!