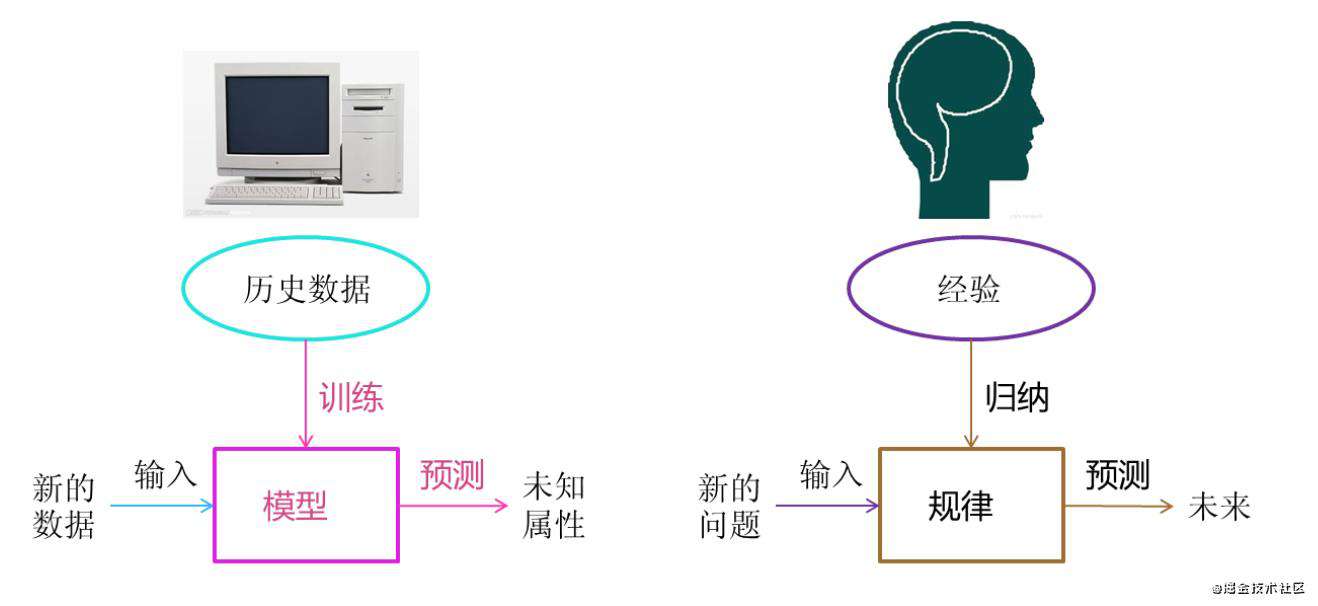
一、基础
1.1 定义
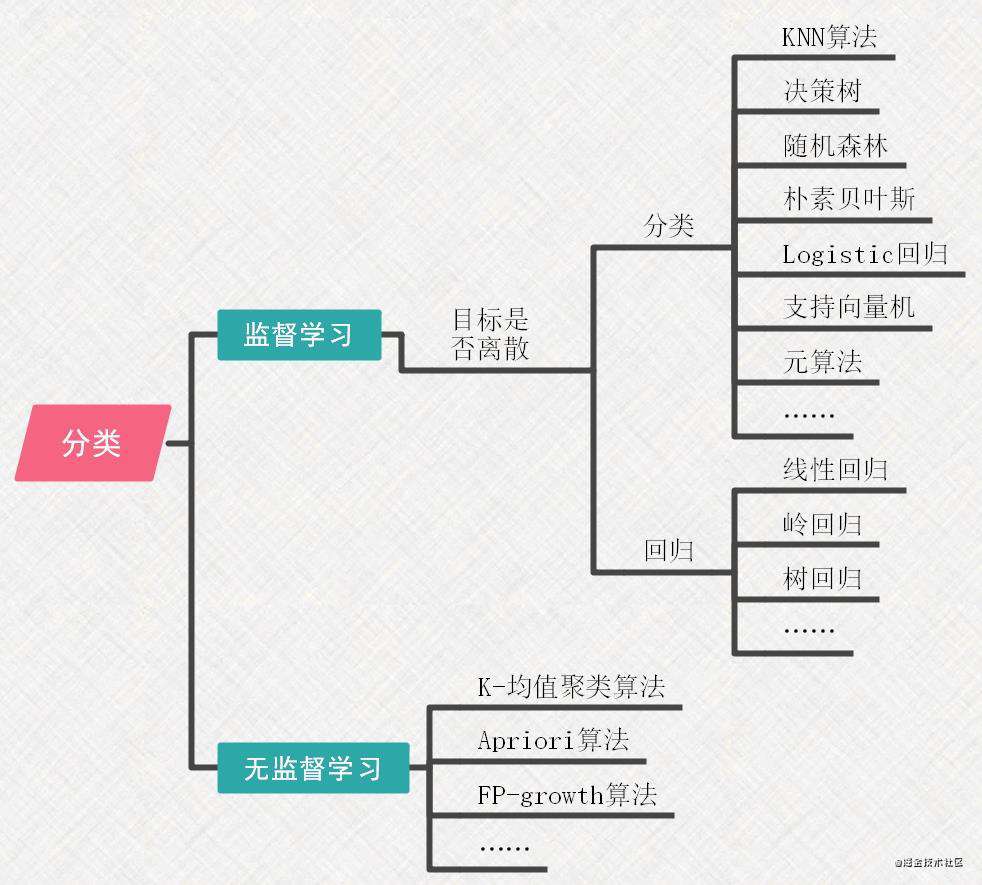
1.2 算法分类
- 监督学习算法——输入数据是由输入特征值和目标值所组成。
- 无监督学习算法——输入数据是由输入特征值和目标值所组成
1.3 如何选择合适算法
- 确定使用机器学习算法的目的。
- 若想要预测目标变量的值——监督学习算法
- 目标变量为离散型——分类算法
- 目标变量为连续型——回归算法
- 若无目标变量值——无监督学习
- 将数据划分为离散的组是唯一需求——聚类算法
- 除将数据划分为离散的组,还需要估计数据与每个组的相似度——密度估计算法
- 若想要预测目标变量的值——监督学习算法
- 需要分析或收集的数据是什么,了解其数据特征
- 特征值是离散型变量还是连续型变量
- 特征值中是否存在缺失的值
- 何种原因造成缺失值
- 数据中是否存在异常值
- 某个特征发生的频率如何
- ……
1.4 整体流程
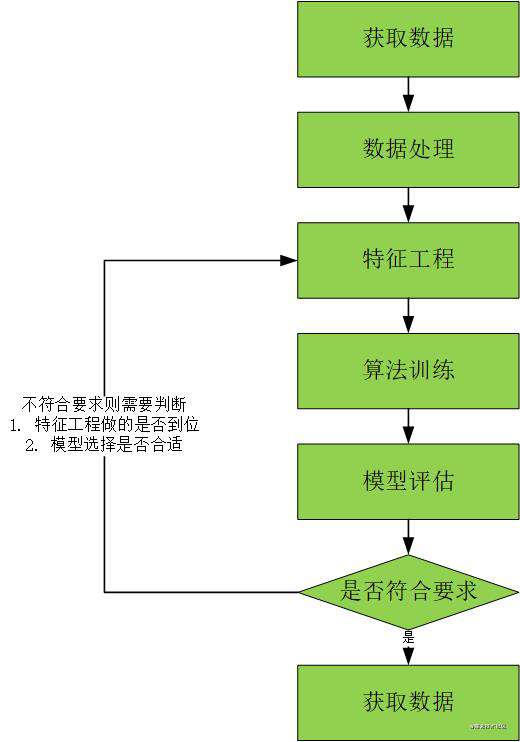
- 获取数据
- 数据处理
- 特征工程
- 算法训练
- 模型评估
- 应用
二、特征工程
注:特征工程是一个很深的学科,此处不展开阐述。
2.1 特征提取
2.2 特征预处理
- 量纲不同:特征可能具有量纲,导致其特征的规格不一样,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征,需要进行无量纲化处理。
- 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,需要进行二值化处理。
- 定性特征不能直接使用:某些机器学习算法和模型只接受定量特征的输入,则需要将定性特征转换为定量特征,可通过哑编码实现。
2.2.1 无量纲化
- 归一化
- 定义
对原始数据进行线性变换,使得结果映射到[0,1]之间。 - 计算公式
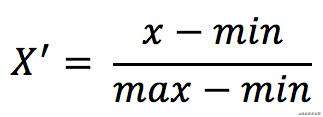
- 特点
最大最小值容易受到异常点影响,稳定性较差。
- 定义
- 标准化
- 定义
将原始数据进行变换到均值为0、标准差为1的范围内 - 计算公式
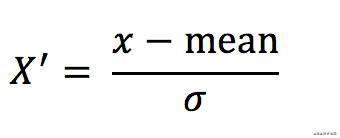
- 特点
较少的异常点对结果影响不大,稳定性较好。
- 定义
2.2.2 定量特征二值化
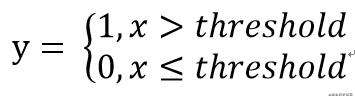
2.2.3 定性特征哑编码
- 无辫子 ====》[1, 0, 0, 0]
- 一个辫子 ====》[0, 1, 0, 0]
- 两个辫子 ====》[0, 0, 1, 0]
- 多个辫子 ====》[0, 0, 0, 1]
2.3 特征降维
2.3.1 特征选择
- 特征是否发散:若某特征不发散(例如方差接近为0),则认为该特征无差异。
- 特征与目标的相关性:优先选择与目标相关性较高的特征。
2.3.1.1 Filter(过滤法)
一、低方差特征过滤

二、相关系数法
- 当r > 0时表示两变量正相关
- r < 0时,两变量为负相关
- 当|r|=1时,表示两变量为完全相关
- 当r=0时,表示两变量间无相关关系
- 当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱

2.3.1.2 Wrapper(包装法)
- 递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征选择出来,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
2.3.1.3 Embedded(集成法)
注:该方法与算法强相关,所以在算法实现的时候进行阐述。
2.3.2 PCA(主成分分析法)
一、 优缺点
- 优点:
- 降低数据的复杂性,识别最重要的多个特征
- 仅需方差衡量信息量,不受数据集以外的因素影响
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素
- 计算方法简单,主要运算式特征值分解,易于实现
- 缺点:
- 可能损失有用信息(由于没有考虑数据标签,容易将不同类别数据完全混合在一起,很难区分)
二适用数据类型——数值型数据
2.3.3 LDA(线性判别分析法)
- 优点:
- 在降维过程中可以使用类别的先验知识经验
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优
- 缺点:
- LDA不适合对非高斯分布(非正态分布)样本进行降维
- LDA降维后可降为[1, 2,……,k-1]维,其中k为类别数
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好
- LDA可能过度拟合数据
参考文献
- 特征工程到底是什么
- LDA和PCA降维
- 机器学习实战
1.如果觉得这篇文章还不错,来个分享、点赞吧,让更多的人也看到
2.关注公众号执鸢者,领取学习资料(前端“多兵种”资料),定期为你推送原创深度好文
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!