
小编一直在更新文章,主要还是把更多的python知识分享给小伙伴们,当然小编也在写python文章的同时,不断加深了对Python的理解。讲了这么多篇的scrapy框架,主要是为了之后抓取数据,搭建python爬虫做准备的。听到这里很多小伙伴是不是恍然大悟,接下来一起学习搭建方法吧。
制作爬虫,总体来说分为两步:先爬再取。
也就是说,首先你要获取整个网页的所有内容,然后再取出其中对你有用的部分。
要建立一个Spider,你必须用scrapy.spider.BaseSpider创建一个子类,并确定三个强制的属性:
name:爬虫的识别名称,必须是唯一的,在不同的爬虫中你必须定义不同的名字。
start_urls:爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse():解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL。
创建douban_spider.py文件,保存在douban\spiders目录下。并导入我们需用的模块
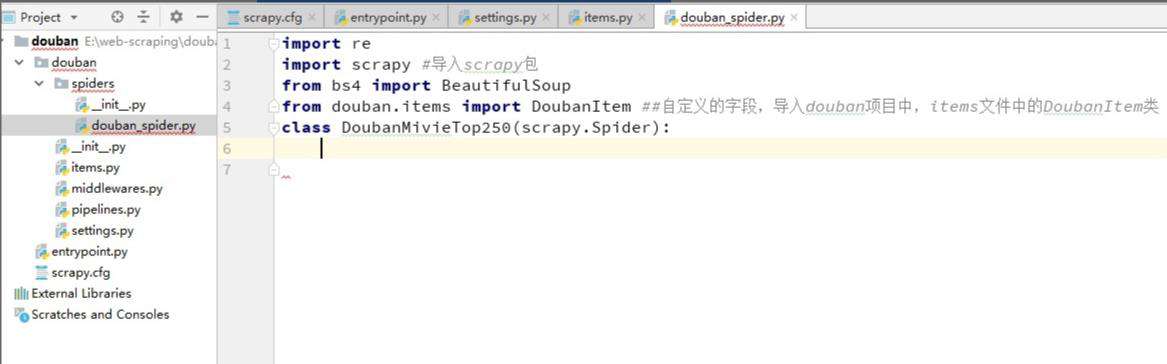
编写主要模块:
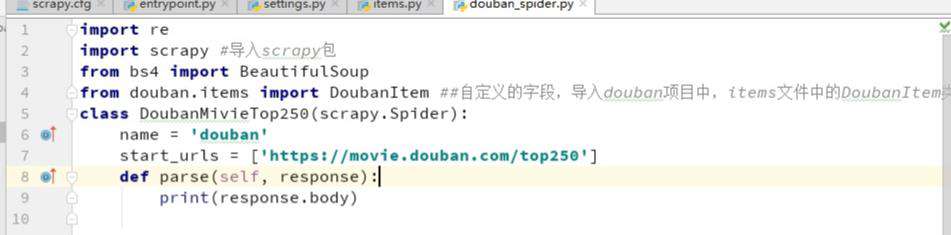
然后运行一下,
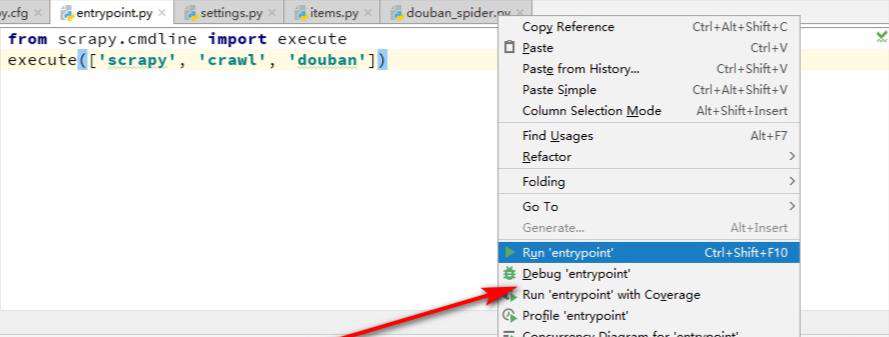
会看到有403错误,是因为我们爬取的时候没加头部导致的:
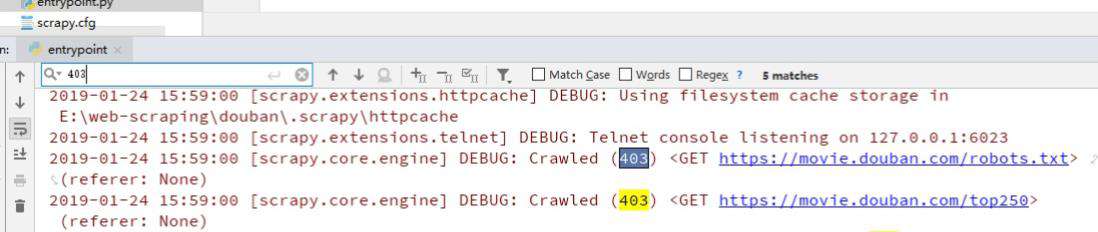
我们来伪装一下,在settings.py里加上USER_AGENT:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
再次运行,即可看到正确结果。
看完本篇的文章,相信小伙伴们对用scrapy框架构建python爬虫有了一定的了解,还没搭建好的小伙伴也不用着急,多尝试找寻搭建的方法。更多Python学习推荐:起源地模板网教学中心。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!